
Claims history plays a crucial role in the insurance underwriting process. This history usually comes in the form of loss run reports generated by insurance carriers. It summarizes the claims an insured business or individual has made while covered by a particular policy.
This process is crucial for P&C insurers as it enables them to identify potential hazards or risks, adjust policy coverage, and take measures to mitigate future losses.
The Prominent Role of Loss Run Reports
Loss run reports are required when a policyholder intends to switch to a new insurer or is nearing their policy renewal. These reports can be thought of as the insurance industry's version of credit scores. Just as a bank reviews your company's credit score before extending a loan, an insurance provider examines your loss history before granting coverage.
Loss run reports contain information regarding the policyholder's claims history. By assessing the number and type of claims made, you can customize the policy and fix a premium for the policyholder.
A loss run report would certainly include the following details:
- Policyholder’s name
- Policy number
- Policy term
- Loss report valuation date
- Date of claim
- Incident description (reason for claim)
- Type of claim (insurance policy)
- Amount paid to date by the insurer in settlement costs, property damage, and other expenses
- Amount the insurer has kept aside for future costs (reserve funds)
- Claim status - open or closed
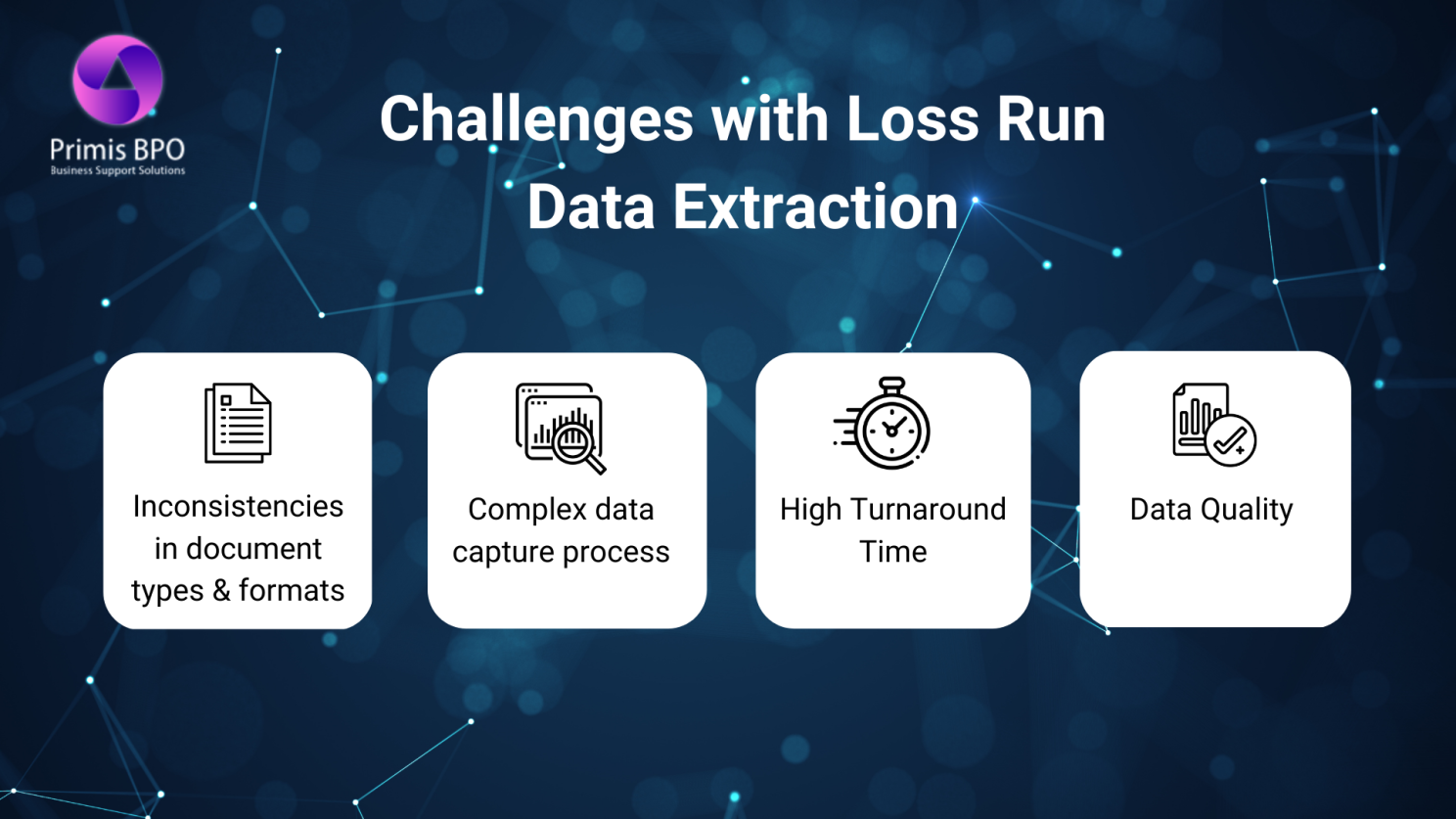
Intricacies of Loss Run Data Extraction - A Closer Look
Loss run reports come in diverse file formats and structures with no standardization, usually PDFs. To perform risk analysis, underwriters have to manually extract, identify, and store the values of critical fields from these reports. They have to open each document, look for key values, and populate a spreadsheet. This manual processing of unstructured reports can be time-consuming and exhausting, resulting in delays and inaccuracies in claim processing.
Let’s have a closer look at the intricacies of loss run data extraction and key factors that can affect the accuracy of the data.
Data Availability
Storing data in different formats and systems makes it difficult to extract and integrate it. Moreover, some insurers may not provide loss run data in a standardized format, which makes it challenging to analyze the data accurately.
Data Quality
Cleaning the data before analyzing it is essential, as it may not always be accurate or complete. For example, claims adjusters may not always record all the details of a claim and leave the loss run report incomplete. Furthermore, different adjusters may use different codes and terminology to describe similar events, leading to inconsistent data. Therefore, it is essential to validate thoroughly even when loss run data is available.
Data Integration
Integrating the loss run data with other data sources such as financial data, customer data, and market data is often necessary to get a complete picture of risk. However, this process can be challenging due to different formats and structures.
Data Analysis
Analyzing the data after extraction is needed to identify trends and patterns. However, analyzing loss run data can be challenging due to the large volumes of data involved as well as the complexity of the data. It is essential to have advanced data analysis tools and techniques to extract meaningful insights.
While traditional loss run data extraction methods have been used for many years, they are not as efficient or accurate as modern digital methods. It’s better to extract the data automatically!
Automated Data Extraction in the P&C Insurance Industry
As we see through the aforementioned challenges, it is evident that collecting all the loss run reports while precisely extracting data from them is a demanding undertaking. Therefore, automating this process can be a valuable solution for inputting the data into an underwriting system.
Artificial intelligence and machine learning can be leveraged to extract loss run data from reports that come in various file formats and structures.
Also, data capture isn't something new! But the level of accuracy required in insurance data extraction means only contemporary methods will do. This brings us to optical character recognition (OCR). Let’s discuss it in detail.
OCR - Extracting Data from Insurance Documents Accurately
Claims processing, being primarily a manual process, is also prone to errors and inefficiencies, further driving up the insurers’ operating costs. According to McKinsey, claims management process is predominantly paper-based and rarely end-to-end digitized, accounting for 50% to 80% of premium revenues.
With OCR, you can extract data from disparate sources and transform it into a format that backend systems can analyze and interpret; a simple process known as ETL (extract, transform, and load).
In simple terms, your computers can scan images of handwritten or typed documents and convert this text into computer-readable text. When paired with natural language processing, or NLP, technology, computer systems can read documents, understand where various data points belong in a structured format, and log them for later analysis.
The benefits of using automation in loss run data extraction are numerous, including:
- Time-saving: Allows you to process large volumes of data quickly and efficiently, freeing up staff for other essential tasks.
- Automated data extraction: Enables you to access policy quotes and comparisons quickly.
- Improved data quality: Enhances the quality of your insurance service with fewer errors and inconsistencies.
- Informed decision-making: Aids you in making informed decisions about risk management and other critical issues with timely and accurate customer information.
Understanding Automated Loss Run Data Extraction with Use Case
The Situation: “Company A," a leading commercial P&C insurer, relied on manual processing to understand its insurer's documents. Processing loss runs quickly was difficult for them, as these documents had a high degree of variability.

The Solution
“Company A” implemented a bot to speed up and complete the entire loss-run data extraction process. With that, they not only saved a lot of time but also increased customer satisfaction and reduced costs.
The Solution-Methodology: Here’s how the bot works:
- Logs into the existing application or system to perform various tasks like accessing mailboxes, reading emails, and classifying and downloading attachments.
- Uses existing APIs to move certain files and folders.
- Extracts content from files, such as forms, PDFs, and spreadsheets.
- Scrapes/ gathers data from web portals and images while working within virtual and Citrix environments.
- Indexes information and puts it through a workflow queue to generate a report.
- Provides on-demand reports to agents for making informed decisions.
The Result
By automating loss run data extraction, “Company A” reported a reduction in error rate with increased productivity and ROI.
Wrapping Up
Loss-run data extraction is a critical component of the P&C insurance industry, providing insurers with the information they need to manage risk, set premiums, and settle claims effectively.
It is an essential tool for insurers in the claims settlement process. Claims adjusters can use this data to evaluate claim validity, estimate the potential payout, and identify any patterns or trends in the insured's loss history. This can help insurers make more informed and accurate decisions about claim settlements and reduce fraudulent activities.
Don't wait to automate your loss run data extraction process! Connect with our experts to unlock the value of your unstructured data.
Recent Blogs

The AI FTE Approach to Property Risk Assessment

Optimizing Auto Insurance Underwriting Through Outsourced AI-Driven Risk Intelligence

[Checklist] From Traditional BPO to Digital Powerhouse: 6 Capabilities Your Tech-Enabled Outsourcing Partner Must Have

Outsourcing AI-Enabled Property Risk Analysis

Outsourcing AI-Powered Risk Assessment for Insurance Optimization



